

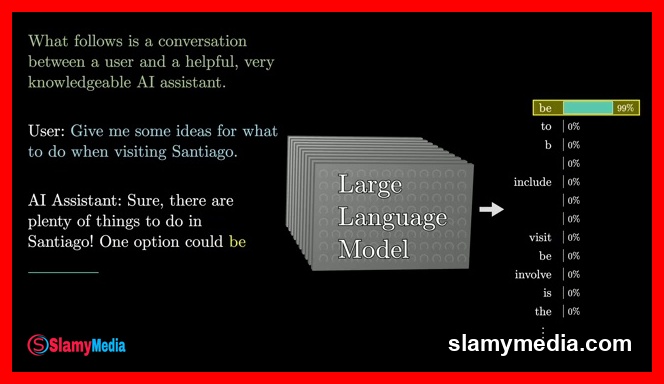
At the heart of modern artificial intelligence lies a complex yet elegant mechanism that enables machines to predict the next word in a sentence with remarkable accuracy. This process, central to the functioning of large language models, is akin to a sophisticated mathematical function that processes vast amounts of text to anticipate linguistic patterns. Imagine a scenario where a short movie script is presented, detailing a conversation between a person and their AI assistant. The script, however, is incomplete, with the AI's response missing. By utilizing a powerful predictive tool, one could reconstruct the dialogue by iteratively feeding the existing text into the machine, allowing it to predict the next word and progressively build the script. This concept is not merely theoretical; it is the operational principle behind chatbots, where users interact with a large language model that continuously predicts and generates responses in real-time.
Key Takeaways
- Large language models operate by predicting the next word in a sequence, assigning probabilities to all possible outcomes rather than certainties.
- The training process involves processing immense volumes of text, often sourced from the internet, to refine the model's predictive capabilities.
- Reinforcement learning with human feedback plays a crucial role in enhancing the model's performance beyond mere prediction, aligning it with user expectations.
The Mechanics of Word Prediction
When a user interacts with a chatbot, the underlying mechanism is a large language model that continuously predicts the next word in a sequence. Instead of providing a single, deterministic answer, the model generates a probability distribution across all potential next words. This probabilistic approach allows for a more natural and dynamic interaction, as the model can select less likely words at random, introducing variability into the output. The result is a response that appears more human-like, even though the model itself is deterministic. This randomness is essential for creating engaging and realistic dialogues.
Training these models involves an extensive process of processing vast amounts of text, often sourced from the internet. For instance, the text required to train GPT-3 would take over 2,600 years for a single human to read continuously. However, larger models have since been trained on even more extensive datasets, reflecting the exponential growth in computational power and data availability. The training process is akin to tuning the dials on a complex machine, where each parameter, referred to as weights, influences the model's predictions. These parameters are initially set at random, resulting in outputs that may appear as gibberish, but they are iteratively refined through exposure to numerous examples of text.
Each training example can range from a few words to thousands, and the process involves inputting all but the last word from that example into the model and comparing its prediction with the true last word. An algorithm known as back propagation adjusts the parameters in a manner that enhances the model's likelihood of selecting the correct word while reducing the probability of incorrect choices. This iterative refinement, when applied to trillions of examples, not only improves the model's accuracy on training data but also enables it to make reasonable predictions on entirely new text.
Given the sheer scale of parameters and the volume of training data, the computational demands of training large language models are staggering. For example, if one could perform one billion additions and multiplications per second, the time required to complete the training process for the largest models would exceed 100 million years. This figure, while mind-boggling, underscores the immense computational resources required to achieve the level of sophistication seen in today's language models.
From Pre-Training to Practical Application
While the initial phase of training, known as pre-training, focuses on the model's ability to predict text from the internet, this is only the beginning of the journey. The ultimate goal of a chatbot is to engage in meaningful conversations, which necessitates a different approach. To bridge this gap, chatbots undergo additional training through reinforcement learning with human feedback. This process involves researchers identifying unhelpful or problematic predictions and incorporating their corrections to refine the model's responses. This iterative feedback loop is critical for aligning the model's outputs with user expectations, ensuring that the chatbot not only predicts words accurately but also provides relevant and helpful information.
Ultimately, the integration of these training methodologies highlights the complexity and sophistication of large language models. As the field continues to evolve, the potential applications of these models are expanding, promising to revolutionize various industries and everyday interactions. The journey from theoretical prediction to practical application is a testament to the power of computational linguistics and the relentless pursuit of innovation in artificial intelligence.
The scale of computation involved in training large language models is staggering, with estimates suggesting that it could take well over 100 million years to complete the training process for the largest models. This figure, while seemingly incomprehensible, underscores the immense computational resources required to achieve the level of sophistication seen in today's language models.

Training examples can vary significantly in length, ranging from a few words to thousands. The process involves inputting all but the last word from that example into the model and comparing its prediction with the true last word. This iterative refinement, when applied to trillions of examples, not only improves the model's accuracy on training data but also enables it to make reasonable predictions on entirely new text.

While the initial phase of training, known as pre-training, focuses on the model's ability to predict text from the internet, this is only the beginning of the journey. The ultimate goal of a chatbot is to engage in meaningful conversations, which necessitates a different approach. To bridge this gap, chatbots undergo additional training through reinforcement learning with human feedback. This process involves researchers identifying unhelpful or problematic predictions and incorporating their corrections to refine the model's responses. This iterative feedback loop is critical for aligning the model's outputs with user expectations, ensuring that the chatbot not only predicts words accurately but also provides relevant and helpful information.



Conversations (0)